
🔧 Gemini 2.5 模型系列詳解:性能更強,成本更省

在本次 Google I/O 發表中,Gemini 2.5 系列模型帶來多項實質升級,特別針對語意理解、多模態推理與部署成本進行優化,讓 AI 應用更加輕量化與彈性化。三款不同版本依據應用情境設計,滿足企業與開發者在效能與成本間的平衡需求:
▍Gemini 2.5 Flash(0520 預覽)
- 採用「DSQ(動態共享配額)」設計,可依任務動態調配運算資源,提升效能同時降低成本。
- 多模態理解與上下文掌握能力提升,適合用於長內容摘要、複雜推理與混合輸入。
- 已整合 WebSearch(支援 Google 搜尋強化推理)與「隱式緩存」功能,可自動避開重複 token 計費,最高可省 75% 成本。
- GA(正式版)將支持微調(Fine tuning)功能,開放客戶轉換預覽版與 GA 版本。
▍Gemini 2.5 Pro(0506 預覽)
- 預設為高精度模型,適用於高要求語意任務,目前仍在進行客戶回饋迭代。
- 將支援「思考預算(Thinking Budgets)」功能,用以控制推理過程中可使用的資源與時間,降低長輸出任務成本。
- 搭配 API 將推出「思考摘要(Thinking Summaries)」,可理解並快速總結思考歷程,適合自動化決策流程。
▍Gemini 2.5 Flash-Lite(開發中)
- 將登陸 Vertex AI,為資源受限裝置或邊緣計算場景打造的輕量模型。
- 上市時間未定,預期將補足中低資源場景下的生成需求。
總結來說,Gemini 2.5 系列強調「效能 × 經濟」雙重進化,適用從高端企業決策工具,到一般應用系統的 AI 模型需求。這些技術上的微調與補強,也將成為 Google 把握生成式 AI 市場主導權的關鍵支點。
🧠 GenAI Media 系列更新:多模態生成邁向影音創作新紀元
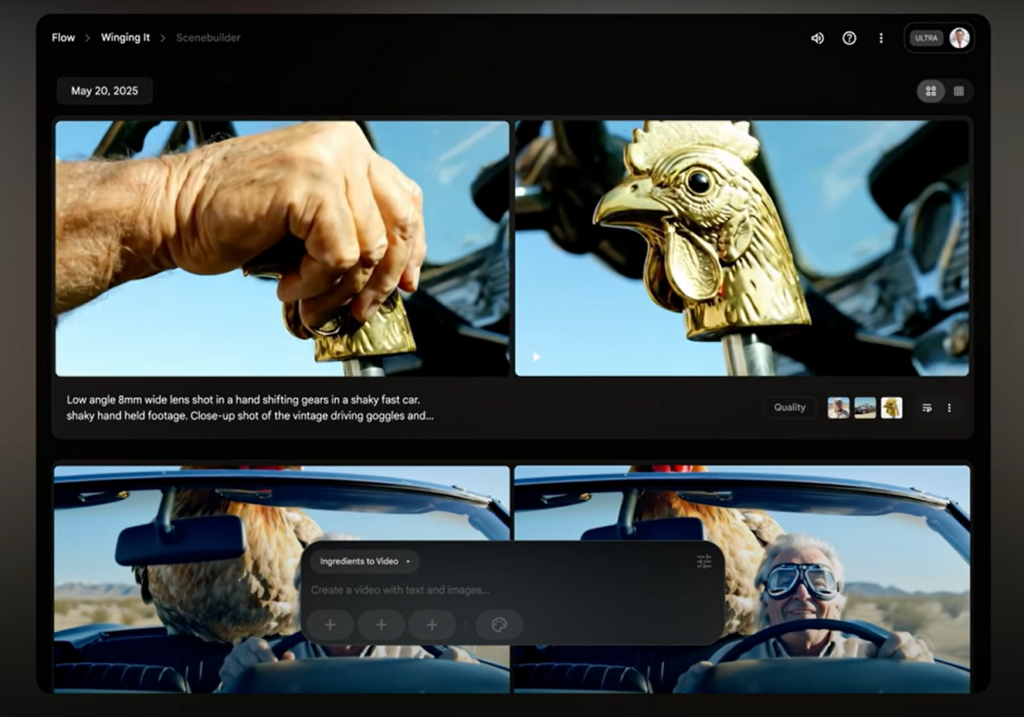
Google 在本次 Google I/O 2025 中,針對 GenAI Media 系列模型全面升級,涵蓋影片生成、圖像生成、音樂創作與語音合成,為創作者、內容平台與多媒體應用提供強大支援。
🎬 Veo 3.0:新一代影片生成模型
Veo 3.0 是 Google 最新推出的影片生成模型,具備強大的動作理解與鏡頭語言掌握能力,可透過輸入文字或圖像生成影片,並可搭配語音、音效與背景音樂,輸出完整的多模態影片內容。與前一代相比,Veo 3 在畫質、運鏡流暢度與多語支援上皆顯著升級,特別適合用於敘事動畫、產品展示與影音廣告等場景。
另外 Flow 是 Google 最新推出的 AI 創作平台,設計上結合了多種生成式工具,能協助創作者無縫整合 Veo、Imagen 等模型進行影片、圖像與音訊內容的製作。透過 Flow,使用者可用自然語言指令協調不同 AI 模型共同創作,讓整體流程更直觀、高效。
🖼 Imagen 4:圖像細節與語意精度全面升級
Imagen 4 延續 Google 強大的文生圖技術,針對解析度與文字描述能力進行大幅提升。用戶可輸入多語言文本,並選擇更高的輸出解析度(包含 2K),即使在圖像中細緻呈現文字、標籤或微小元素,仍能保持清晰銳利,適用於設計、出版與視覺行銷領域。
🎵 Lyria 2:AI 音樂創作的情感控制器
Lyria 2 是 Google 最新的文字轉音樂模型,可根據輸入的文本描述(如風格、情緒、節奏),生成對應的旋律與音效。用戶無需具備作曲背景,即可產製具故事性與情境感的音樂,廣泛應用於遊戲配樂、廣告、教育影片等多媒體內容中。
🔊 Chirp 3:語音模型拓展至 30 組聲音與新語言支援
Chirp 3 大幅拓展語音樣本庫,從原本的 8 組擴展至 30 組,提供更多語氣、音色與語者選擇,並新增四種語言支援,包括丹麥文(da-DK)、挪威文(nb-NO)、瑞典文(sv-SE)與芬蘭文(fi-FI),進一步拓展全球化應用版圖。
🔊 Gemini Live API 與語音生成全面升級:打造高品質即時語音體驗

為因應企業與開發者對於即時語音互動的需求,Google 在本次 I/O 中重磅更新 Live API 與語音生成模型,提升穩定性、語音品質與多語支援,成為建構語音應用與 AI 對話體系的核心模組之一。
📡 Live API 預覽端點與性能強化
新版 Live API 已導入 預覽端點,針對原生語音對話進行大幅優化,提升即時串流語音的傳輸效率與穩定性,同時表現力與語氣流暢度明顯增強,為多輪對話或直播場景提供更穩固的語音底層支撐。
🎙 原生語音模型更新:高品質自然語音輸出
目前 Live API 採用多種語音生成模型進行測試,包括 Flash 版與新版 TTS 模型。這些模型具備以下關鍵特色:
- 語音品質提升:音色自然,語氣連貫,更具人類語者語感
- 語種拓展:支援 24 種語言輸出
- 功能強化:
- 主動語音(能辨識上下文語義發起語音)
- 情感語音(呈現語者情緒變化)
- VAD 與端點檢測可調控:提升語音節奏控制力
🛠 模型部署與應用方式
這些語音模型現已整合至 Google AI Studio,並預計陸續在 Vertex AI 中開放,企業與開發者可透過簡單 API 呼叫,快速打造高互動語音應用,如客服對話、語音助手、教育語音教學平台等。
🧪 Gemini 實驗計畫前瞻:探索 LLM 智能與工具應用邊界
除了正式推出的模型與 API 工具外,Google 也公開了三項具備前瞻性與探索性的 Gemini 實驗專案,聚焦於提升模型思維能力、強化指令控制與加速生成效率。
🖥 Gemini Computer Use:從語言模型走向「電腦操作員」
這是一項基於 Gemini 模型的實驗性能力擴充,搭配 Gemini Action API,可根據語意生成具體操作指令(如開啟應用程式、執行任務等),讓 LLM 模型具備實際控制電腦的能力。
目前已與 Project Mariner 架構接軌,正在有限合作夥伴測試階段。未來將可能納入正式 GA 模型中,或作為獨立端點提供。
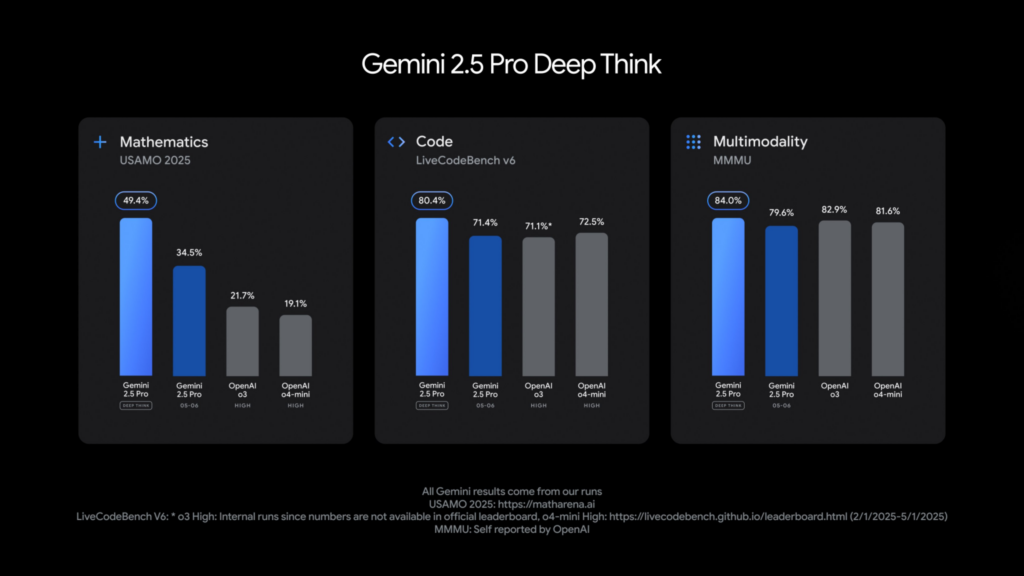
🧠 Gemini Deep Think:推理能力的再進化
此實驗版本專注於打造多路徑思維(Multi-step Reasoning)能力,強化模型在邏輯鏈接、長篇推理與深層語意分析上的表現。
這類模型特別適合用於複雜問答、商業決策建議、程式設計與教學模擬等應用。目前僅限內部與信任測試者試用。
🌀 Gemini Diffusion:生成與編輯的雙強組合
Gemini Diffusion 是一款具備高度彈性與多種應用潛力的圖像生成模型,整合了快速輸出、多樣風格、內嵌編輯與混合控制等功能。
這項模型仍處於早期研究階段,但已展現出跨越「一次性輸出」限制、走向可調式視覺創作平台的潛力。
🎮 Firebase AI Logic for Unity:讓遊戲開發者無痛整合生成式 AI
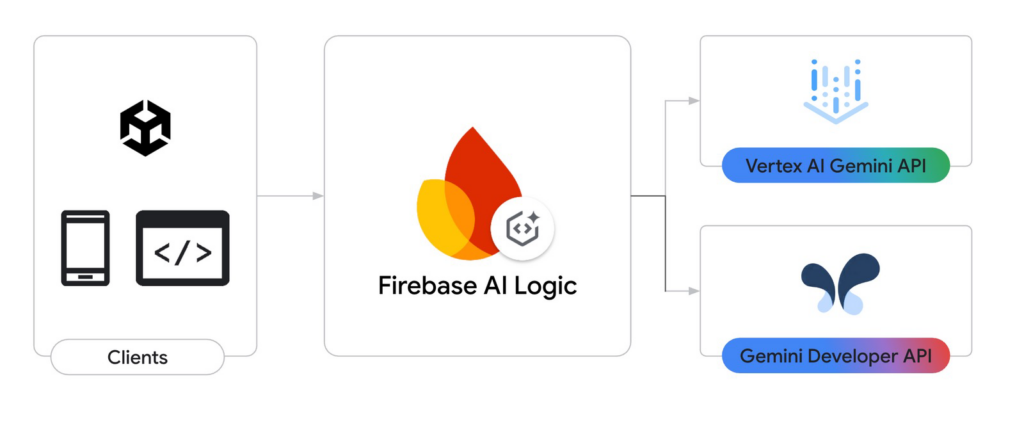
Google 推出全新 Firebase AI Logic for Unity SDK,幫助開發者輕鬆將由 Gemini 模型驅動的生成式 AI 能力整合至 Unity 所開發的遊戲與 Android XR 應用中,徹底降低技術門檻,加速 AI 實用化落地。
這套 SDK 架構清晰,透過 Firebase 平台作為邏輯中介,可連接:
- Vertex AI Gemini API:支援企業級部署、模型微調與安全控管
- Gemini Developer API:適合創作者與中小型團隊靈活試作與快速測試
透過這項整合,開發者能快速實現如下一系列生成式功能:
- 語音與文字驅動的互動式角色行為(智慧 NPC)
- 根據描述即時生成場景圖與道具素材
- 玩家輸入觸發 AI 編劇或情境延伸
- 遊戲內指令與策略建議(結合 Agent 工具)
Firebase 作為橋接者,也提供了熟悉的雲端部署、用戶管理與資料儲存機能,讓整體整合工作更直覺、模組化。
這意味著從獨立開發者到大型遊戲公司,都能在熟悉的 Unity 環境中享受到生成式 AI 的革新效益,進一步擴展遊戲敘事深度、互動自由度與創作效率。
🕹 Gemini 加速遊戲與 XR 體驗革新:三大應用場景全面升級

隨著 Firebase AI Logic SDK 整合 Gemini API,Google 也同步公開了三大典型應用情境,展示生成式 AI 如何在遊戲與沉浸式體驗(XR)中扮演關鍵角色,改變開發方式與玩家互動模式。
🎙 1. 互動式對話敘事(Interactive conversational storytelling)
透過語音與文本互動介面,玩家可針對故事中角色、場景或事件提出指令或提問,Gemini 將即時生成對應的語音回應與劇情發展。
這種雙向的語意驅動互動,不僅強化沉浸感,更能為線性遊戲與教育內容注入多層敘事變化。
- Gemini 核心技術:多模態雙向串流(Multimodal bidirectional streaming)
🎨 2. 動態圖像生成(Dynamic image generation)
玩家可透過語音或文字描述場景、物品或角色外觀,Gemini 會即時生成 2D 素材供遊戲或應用使用,無須美術人員介入即可構築豐富視覺內容。
此技術特別適合用於沙盒遊戲、角色自訂、創作平台與快速原型製作流程。
- Gemini 核心技術:圖像生成(Image generation)
🧠 3. 智能化 NPC(Intelligent NPCs)
NPC 不再是預設對話的靜態角色,而是能夠根據玩家輸入內容即時生成語音與回應劇情,甚至根據場景資料與玩家行為產生個性化互動。
例如玩家靠近一名守衛時,他可能會因應時間、任務進度與背景設定發出警告或提供任務線索。
- Gemini 核心技術:多模態輸入與文字輸出(Multimodal input & text output)
📊 Claude 模型多雲平台效能比較:Google Vertex 表現穩定且領先
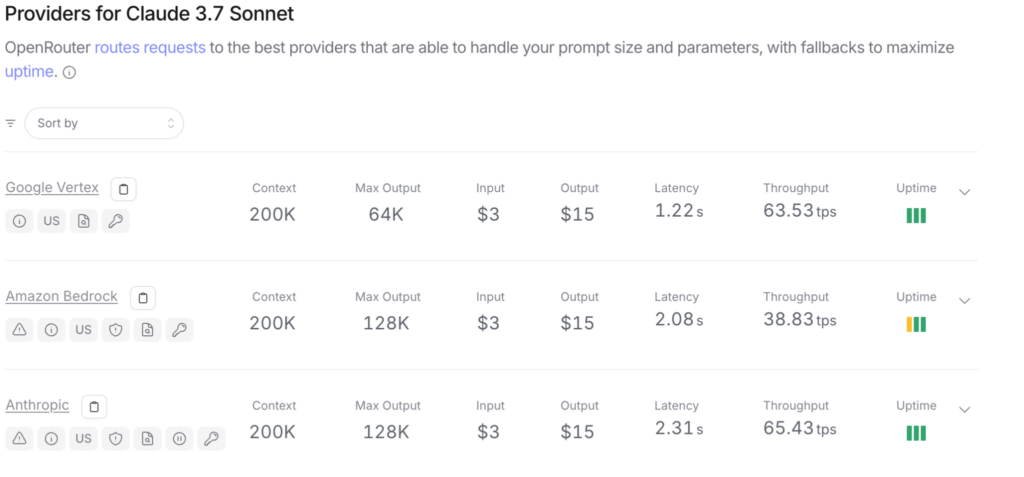
在選擇 Claude 模型的部署平台時,效能與穩定性成為企業導入 AI 能力的關鍵參考指標。根據 OpenRouter 提供的即時資料,我們針對 Claude 3.7 Sonnet、Claude 4 Sonnet 與 Opus 三個版本,在三大主要平台進行效能比較,重點如下:
Claude 3.7 Sonnet
- Google Vertex:
- 延遲:1.22 秒(最低)
- 吞吐率:63.53 tps(表現極佳)
- 穩定性:3 格滿格(穩定)
- Amazon Bedrock:
- 延遲:2.08 秒
- 吞吐率:38.83 tps(顯著較低)
- 穩定性:中等,部分時間有降級現象
- Anthropic 原廠:
- 延遲略高(2.31 秒),但吞吐率達 65.43 tps
- 整體穩定性良好,但無法自訂或整合企業資源
Claude 4 系列(Sonnet / Opus)
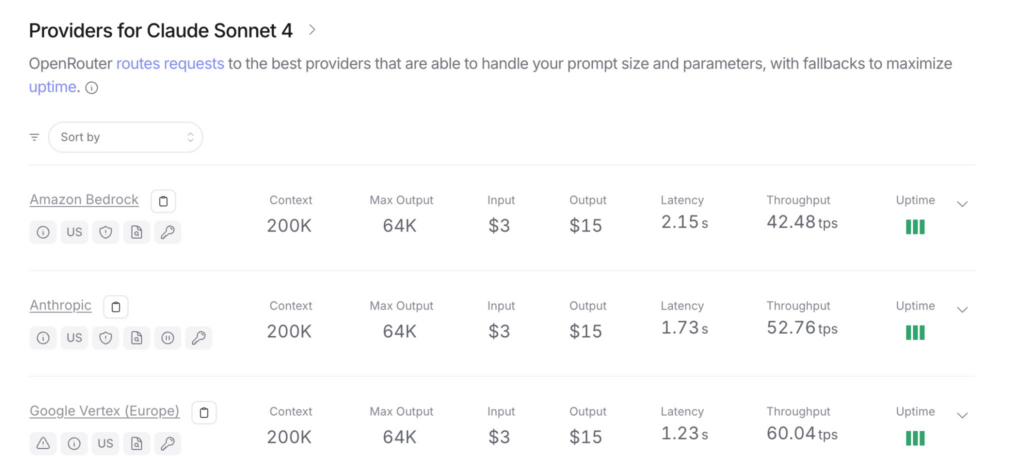
- Claude 4 Sonnet
- Google Vertex 再次取得最低延遲(1.23 秒)與高吞吐率(60.04 tps)
- Bedrock 延遲略高(2.15 秒),吞吐僅 42.48 tps
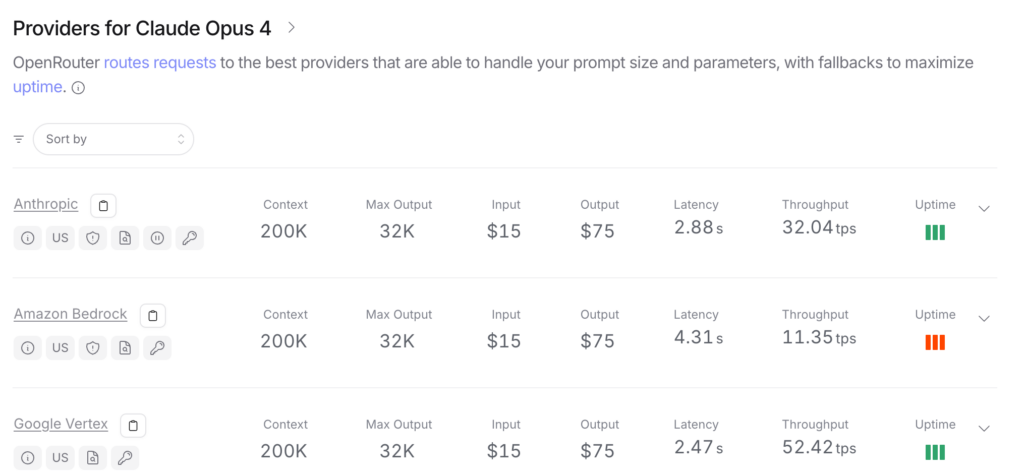
- Claude 4 Opus
- Google Vertex 延遲為 2.47 秒,吞吐 52.42 tps,穩定性優
- Amazon Bedrock 吞吐僅 11.35 tps,延遲高達 4.31 秒,表現明顯落後
- Anthropic 自家平台延遲略高但尚可接受(2.88 秒)
✅ 結語:從模型競速到應用競爭,生成式 AI 正在進入黃金落地期
當語言模型不再只是對話工具,而能驅動圖像、音樂、語音、影片與程式行為時,AI 應用邊界正在快速模糊與拓展。本次 Google I/O 2025 所揭示的重點,是生成式 AI 正式進入「應用競爭」時代——模型能力固然關鍵,但平台穩定性、工具整合性與開發便利性,才是真正主導市場落地的核心。
Gemini 系列不再是單一模型,而是一套跨雲部署、適應多情境的 AI 生產力基礎;從 Firebase 到 Vertex、從創作者工具到企業框架,Google 正以更開放、更實用的姿態,搶佔下一輪 AI 應用的制高點。
未來已來,選對模型,更要選對平台與工具生態。從這一屆 I/O 我們已可看見,生成式 AI 將不只是生成,更是驅動創新與商業轉型的主引擎。
📬 有導入 AI 模型、語音應用、遊戲互動或多雲部署的需求?歡迎聯繫 Elite Cloud 專家團隊,取得一對一技術諮詢與專案評估。


