Amazon S3 is the second most used service in Amazon Web Services and the number one when it comes to storage. It’s an object storage solution that lets you store and retrieve all kinds of data, from documents and images to large-scale backups and data lakes.

Since it’s the foundational storage layer for many AWS architectures, managing S3 cost can quickly become overwhelming. If not properly designed and optimized, expenses can grow out of control. The good news? Amazon S3 comes packed with features that make cost control not just possible but highly effective.
In this guide, we’ll break down how S3 works and show you how to cut down storage costs without sacrificing performance.
1. Understand How S3 Pricing Works
Before you can get into cost optimization, you need to understand key components and how you’re being charged. S3 price isn’t just about how much data you store, but more than that.
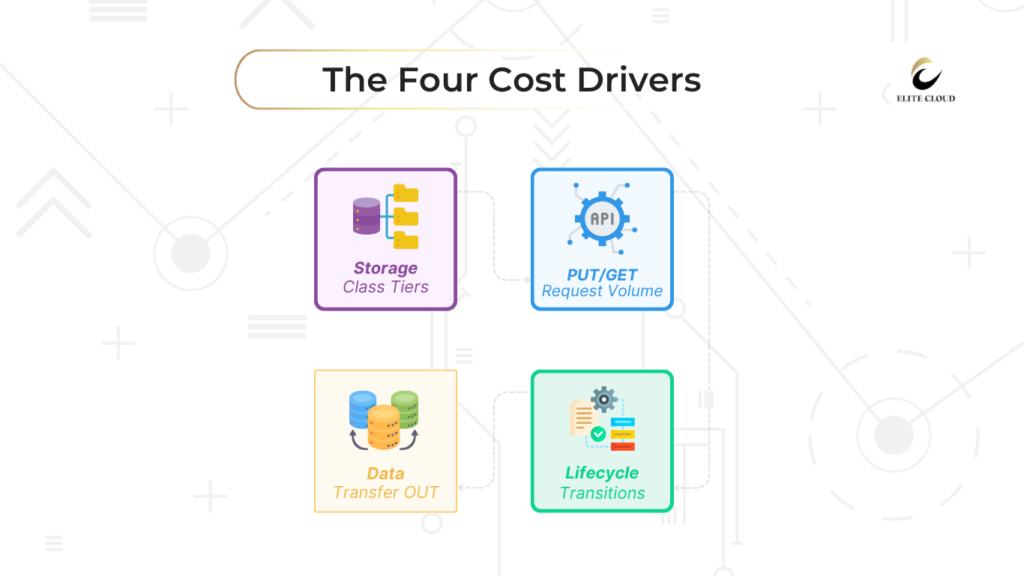
Here are the main components:
Storage Cost
You pay based on the amount of data stored and the storage class (Standard, Intelligent-Tiering, Glacier, and more). Different classes are designed for different use cases and access patterns. We will learn more about classes later in this article.
PUT/GET request
Every interaction like uploads (PUT), downloads (GET), and delete has a cost. Apps that require high frequency access can rack up massive request charges, even with small data volumes.
Data transfer OUT
While any inbound transfer into S3 is free. Data transferred out of S3 to the internet or across AWS regions is charged. Without proper planning outbound data can be very expensive.
Lifecycle transitions
Moving data between storage classes using lifecycle rules may incur transition costs, especially in large volumes of data.
2. Choosing the Right Storage Class
One of the easiest ways to cut your S3 costs is by picking the right storage class for your data. It can cut your storage cost by up to 80%. Not all data needs to live in S3 Standard, yet many businesses keep cold, rarely accessed files there and end up overpaying heavily.
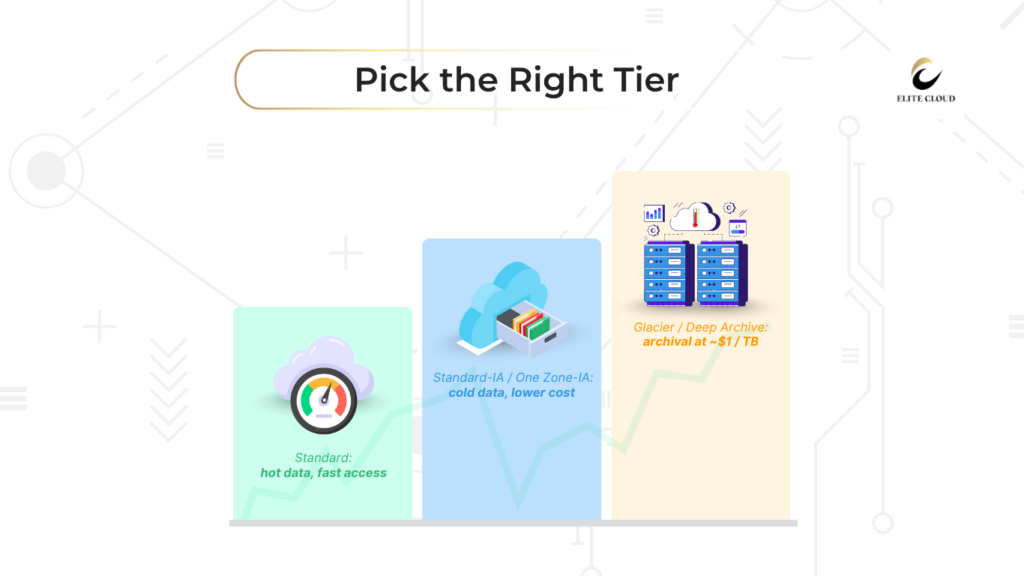
Here’s a quick breakdown of each storage class and when to use them:
S3 Standard vs. Standard-IA Comparison
S3 Standard is great for data you use a lot and need right away. It costs more but is fast and efficient. It’s best for busy websites, streaming, and apps.
S3 Standard-IA is cheaper for data you don’t use often. It’s more affordable but takes longer to get back. It’s perfect for backups and long-term storage.
When to Use S3 One Zone-IA
S3 One Zone-IA is cheaper still, but it’s less reliable. It stores data in one zone, not multiple. You save about 20% compared to Standard-IA.
Use it for backups, data you can easily recreate, or non-critical info. But don’t rely on it for your only copy of important data.
Glacier and Glacier Deep Archive for Long-term Storage
Glacier storage is cheap for data you hardly ever use. It takes a bit longer to get back, but it’s great for archives and media.
Glacier Deep Archive is the cheapest for data you almost never need. It takes 12 hours to retrieve, but storage costs are just $1 per terabyte monthly.
S3 Intelligent-Tiering Benefits
S3 Intelligent-Tiering automatically saves you money on data with unknown usage. It moves data between tiers based on usage, without slowing you down.
This hands-off approach saves you money on storage. You pay a small fee for monitoring, but it’s worth it for unpredictable data.
| Storage Class | Monthly Cost per GB | Retrieval Time | Best Use Case |
| S3 Standard | $0.023 | Immediate | Frequently accessed data |
| Standard-IA | $0.0125 | Immediate | Infrequently accessed data |
| One Zone-IA | $0.01 | Immediate | Non-critical, recreatable data |
| Glacier | $0.004 | 1-5 minutes | Archive data |
| Glacier Deep Archive | $0.00099 | 12 hours | Long-term archive |
*This pricing is subject to change by AWS. Full pricing details on Amazon S3 can be found here.
3. Implementing S3 Lifecycle Policies
Strategic use of lifecycle automation policies can cut your S3 storage costs a lot. These tools manage storage for you, keeping costs low. S3 lifecycle policies run in the background, making smart decisions about your data.
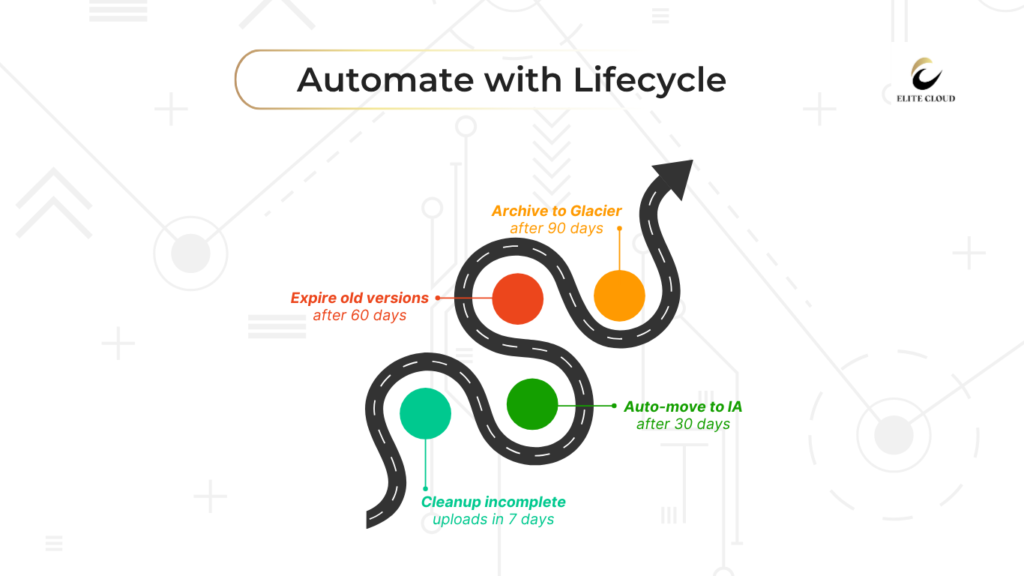
These policies do more than just change storage classes. They handle data archiving and cleanup too. This keeps your costs down and your data organized.
Creating Automated Transition Rules
Automated transitions are key to managing costs. You can set rules to move data to cheaper storage classes. For example, moving files to Standard-IA after 30 days can save up to 40%.
Start with data you use often in S3 Standard. Then, move it to Standard-IA for less frequent use. Finally, archive rarely used data for the biggest savings.
Setting Up Object Expiration Policies
Object expiration policies delete files you no longer need. This stops you from paying for storage on files you don’t use. You can set rules for log files, temporary uploads, and more.
Use graduated expiration for different file types. Log files might expire in 90 days, while backups last a year before deletion.
Managing Incomplete Multipart Uploads
Incomplete uploads can cost you a lot if you don’t clean them up. Lifecycle policies should remove these uploads after 7-14 days.
Find a balance between keeping uploads long enough for retries and not letting them cost too much. Set the cleanup period to fit your needs and budget.
| Lifecycle Action | Recommended Timeline | Cost Impact | Implementation Priority |
| Standard to Standard-IA | 30 days | 40% reduction | High |
| Standard-IA to Glacier | 90 days | 68% reduction | High |
| Glacier to Deep Archive | 180 days | 75% reduction | Medium |
| Multipart Upload Cleanup | 7-14 days | Variable savings | High |
4. Optimizing Data Transfer Costs
Data transfer costs are a big part of your S3 budget. They add up fast when moving data between regions or serving content worldwide. Knowing where these costs come from helps you save money.
Understanding Data Transfer Pricing
AWS charges for data transfer out of S3 based on where it goes and how much. Transfers within the same region are free. But, moving data between regions or over the internet costs money. The more you use, the less you pay per unit.
Putting your EC2 instances in the same region as your S3 buckets saves money. This is especially true for apps that often access data. Using Amazon VPC endpoints also cuts costs by keeping data within AWS.
Using CloudFront for Content Delivery
CloudFront CDN greatly lowers data transfer costs for often-visited content. It stores your S3 objects at edge locations around the world. This can reduce costs by up to 85% for popular content.
Set up CloudFront with the right cache behaviors and TTL settings to save more. Static assets like images, videos, and documents get the most benefit from CDN caching.
Minimizing Cross-Region Transfer Costs
Batching operations and compressing files before transfer can help with cross-region data movement. Placing buckets based on user location also helps avoid long-distance transfers.
For large file uploads, consider using S3 Transfer Acceleration. It’s often cheaper and faster than direct cross-region transfers.
5. Managing S3 Request Costs Effectively
Managing S3 request costs means knowing how your apps use storage buckets. Even though each request costs a little, they add up fast in busy sites. By using smart strategies, you can cut these costs without losing any features.
Use AWS CloudTrail data events or server access logging to watch request patterns. These tools show which operations use the most resources and where you can save.
Reducing PUT and GET Request Frequency
Use smart caching to cut down on GET requests. Make your apps cache often-used items locally or use CloudFront for automatic caching. This way, you avoid making the same request over and over.
Combine small files into big archives before uploading. Instead of uploading many small files, upload a few big ones. This saves on request costs and makes uploads faster.
Batch Operations for Cost Efficiency
Batch operations let you do many tasks at once. Use S3 Batch Operations to handle thousands of objects in one go, not one by one. This can cut request costs by up to 90% for big jobs.
Group similar tasks together when you can. Do batch deletions, updates, and access changes during slow times. This makes things more efficient.
Optimizing API Call Patterns
API optimization means cutting out unnecessary steps in your app. Avoid extra LIST operations and HEAD requests that check if objects exist. Instead, handle errors that assume objects are there unless proven otherwise.
Check how your app interacts with S3 often. Here’s a table with common request types and how to save on them:
| Request Type | Cost Impact | Optimization Strategy | Potential Savings |
| GET Requests | High Volume | Implement caching | 60-80% |
| PUT Requests | Medium | Batch file uploads | 70-90% |
| LIST Operations | Low but frequent | Cache directory listings | 50-70% |
| HEAD Requests | Low individual | Reduce existence checks | 40-60% |
6. Leveraging S3 Storage Lens for Cost Insights
Amazon S3 Storage Lens turns raw data into useful cost insights. It helps you make better decisions for your AWS setup. This tool gives you a clear view of your storage use, showing where you can save money.
The service collects and analyzes data from all your S3 buckets. It shows you this information in easy-to-understand dashboards and reports. You get quick access to storage analytics that highlight which buckets use the most resources.
7. Data Compression and Deduplication Strategies
Data compression and deduplication are key to cutting S3 storage costs. They reduce the data you store, leading to lower bills. With these methods, you can save 30-70% on storage, depending on your data.
Check your data before uploading to S3 for compression chances. Text files, logs, and some media formats compress well.
8. Implementing Cross-Region Replication Cost Controls
Managing cross-region replication costs is key to balancing disaster recovery needs with your AWS spending. Cross-region replication offers vital data protection across different locations. But, it can raise your storage budget without the right cost controls. By implementing strategies wisely, you can keep your disaster recovery strong while controlling costs.
Understanding which data needs geographic redundancy is crucial. Not all data in your S3 buckets needs to be replicated right away. By picking the right data and storage classes, you can protect your data well without spending too much.
9. Versioning and Delete Marker Management
Managing S3 object versions and delete markers is key to keeping costs down in versioned buckets. Object versioning protects your data, but it can lead to hidden costs if not managed well.
Each version of your objects takes up space and costs money. Without watching these costs, they can add up quickly as your data changes.
10. Analyzing Your Current S3 Usage and Costs
Knowing how much you spend on S3 is key to saving money. You can’t cut costs if you don’t know where they go. So, start by doing a deep dive into your S3 usage analysis.
AWS has tools to help you see where your money goes. You’ll find out which buckets use the most resources and what’s costing you extra. This step shows you where you can save the most.

Using AWS Cost Explorer for S3 Analysis
AWS Cost Explorer is your go-to for S3 costs. Go to the dashboard and filter by service to see just S3 charges. You can look at costs by storage class, region, and time.
This tool shows your spending over the last 13 months. You’ll see which storage classes cost the most and when you use the most. Use the grouping features to see costs by bucket tags or accounts.
Identifying High-Cost Storage Patterns
Look for patterns that show where you’re spending too much. Excessive data transfer charges often mean your setup isn’t right. High request costs mean your apps are making too many calls.
Check how your storage classes are set up. Files in S3 Standard that haven’t been accessed in months are a big opportunity. Also, objects in Intelligent-Tiering with regular access might need a manual change.
| Cost Analysis Tool | Primary Function | Best Use Case | Data Retention |
| AWS Cost Explorer | Historical cost analysis | Trend identification | 13 months |
| S3 Storage Lens | Storage metrics | Usage optimization | 30 days free |
| Cost and Usage Reports | Detailed billing data | Granular analysis | Custom period |
| CloudWatch Metrics | Real-time monitoring | Performance tracking | 15 months |
Setting Up Cost Monitoring Alerts
Stay ahead of costs with cost monitoring. Use AWS Budgets to track S3 spending. Set alerts at 80% and 95% of your budget.
Make anomaly detection rules to catch sudden spending increases. These alerts help spot issues like data transfers or storage class mistakes. Set up notifications to reach your team quickly.

Conclusion
Effective AWS storage optimization needs a strategic plan that grows with your business. This guide shows you how to cut storage costs without losing performance.
Start by understanding how you use your storage now. Begin with simple lifecycle policies and the right storage class choices. These steps can save you money right away.
Contact the Elite Cloud Cost Optimization team for doing a free checkup right away.